Toxic Comment Classification
Problem Description
- Multi-class classification problem
-
Natural Language Processing (NLP) task analysing text data
-
Data consists of Wikipedia comments which have been labeled by human raters for toxic behavior.
-
The types of toxicity are:
- toxic
- severe_toxic
- obscene
- threat
- insult
- identity_hate
-
these toxicity labels are binary [0,1] where indicates the rater has labelled the commet toxic
-
text data is in the comment_text column
- Workflow
- clean text
- preprocess text : text -> numerical vector
- Build embedding matrix using GloVe dataset
- use tensorflow to build neural network with embedding layer
Understanding the data
Cleaning Text
-
Real word text data is messy , need to clean it
- Pipeline transformations :
- correct spelling of text
- lowercase
- remove urls, punctuation, html and white space
- with word embedding DO NOT STEM words
def comment_cleaning(x):
"""Apply function to a clean a comment"""
x = x.str.lower().str.strip()
# # romove urls
x = x.str.replace(r'https?://\S+|www\.\S+', '', regex=True)
# remove html tags
x = x.str.replace(r'<.*?>', '' ,regex=True)
# remove punctuation
x = x.str.replace('[{}]'.format(string.punctuation), '', regex=True)
# remove newlines
x = x.str.replace(r'\n',' ', regex=True)
# spell checker
# stop words
x = x.apply(lambda x: ' '.join([word for word in x.split() if word not in (stop_words)]))
return x
Tensorflow text preprocessing
- how big is each word vector
- embed_size = 50
- how many unique words to use (i.e num rows in embedding vector)
- max_features = 20000
- max number of words in a comment to use
- Limit on the length of text sequences.
- Sequences longer than this will be truncated and less than it will be padded
- maxlen = 100
Tokenising
- Need to tokenise the text, split strings into individual words
- fit the tokenizer on the train set
- then apply it to both train and test set
- word index is built on the training set
- oov token used to replace words not in training set, but in test set
- to mantain length of sequence of test data
tokenizer = Tokenizer(num_words=max_features,oov_token='<OOV>')
tokenizer.fit_on_texts(X_train['comment_text'].values)
X_train = tokenizer.texts_to_sequences(X_train['comment_text'].values)
X_val = tokenizer.texts_to_sequences(X_val['comment_text'].values)
Padding
- designed to handle sentences of different lengths
- ragged tensor
- or padding
- so the dimensions of the tensor are of the same length
-
2 * 2 etc
-
padding= post : add the zeros at the end of the sequence to make the samples in the same size
-
truncating= post setting this truncating parameter as post means that when a sentence exceeds the number of maximum words drop the last words in the sentence instead of the default setting which drops the words from the beginning of the sentence.
- malen for padding should be same in test and train set
Building embedding matrix using GloVe dataset
- Can build own embedding matrix from corpus
- However corpus of data is relatively small
- Therefore used pre-trained embedding layer to initialise wieghts
embeddings_index = {}
f = open(EMBEDDING_FILE)
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
#Found 400000 word vectors.
embedding_matrix = np.zeros((max_features, embed_size))
for word, i in tokenizer.word_index.items():
if i < max_features:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vecto
Model Building
inputs = tf.keras.Input(shape=(maxlen,))
x = Embedding(max_features, embed_size, weights=[embedding_matrix])(inputs)
x = Bidirectional(LSTM(50, return_sequences=True, dropout=0.1, recurrent_dropout=0.1))(x)
x = GlobalMaxPool1D()(x)
x = Dense(50, activation="relu")(x)
x = Dropout(0.1)(x)
x = Dense(6, activation="sigmoid")(x)
model = Model(inputs=inputs, outputs=x)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
earlystopping = callbacks.EarlyStopping(monitor ="val_loss",
mode ="min", patience = 3,
restore_best_weights = True)
history = model.fit(X_train, y_train, batch_size=512, epochs=50, validation_data=(X_val, y_val),callbacks=[earlystopping])
Evaluation
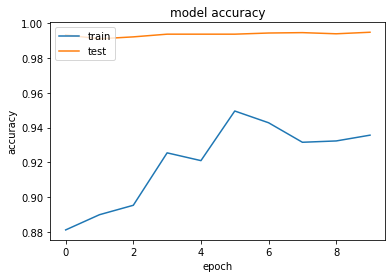
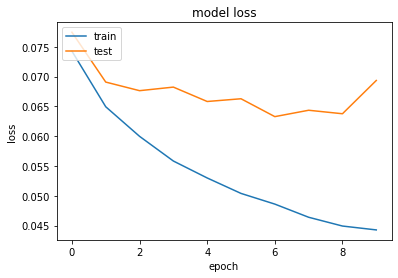
- accuracy on the validation set ~ 0.95